Bayangkan internet sebagai sebuah kota besar dengan jutaan gedung yang mewakili berbagai situs web. Di kota ini, Google punya “robot penjelajah” yang disebut Googlebot. Robot ini tugasnya berkeliling kota setiap hari untuk mengunjungi gedung-gedung baru, melihat apa yang ada di dalamnya, dan mencatat informasi penting untuk dibawa pulang ke “kantor pusat Google”.
Proses ketika Googlebot mengunjungi halaman-halaman web ini disebut crawling. Crawling adalah langkah pertama dari tiga proses utama dalam SEO teknis: crawling, indexing, dan ranking. Nah, tanpa crawling, halaman kamu nggak akan bisa masuk ke indeks Google. Artinya, halaman itu nggak akan pernah muncul di hasil pencarian! Ia mulai dari satu halaman, lalu mengikuti tautan yang ada untuk menemukan halaman lainnya. Semua ini terjadi secara otomatis dan sangat cepat.
Mengapa Crawling Itu Penting?
Kalau website kamu tidak ter-crawl, maka Google tidak akan tahu kalau website kamu ada. Artinya, halaman kamu tidak akan muncul di hasil pencarian. Tanpa crawling, tidak akan ada indexing. Tanpa indexing, kamu tidak bisa mendapatkan trafik dari Google.
Jadi, crawling adalah langkah awal dari seluruh proses SEO.
Bagaimana Proses Crawling Bekerja?
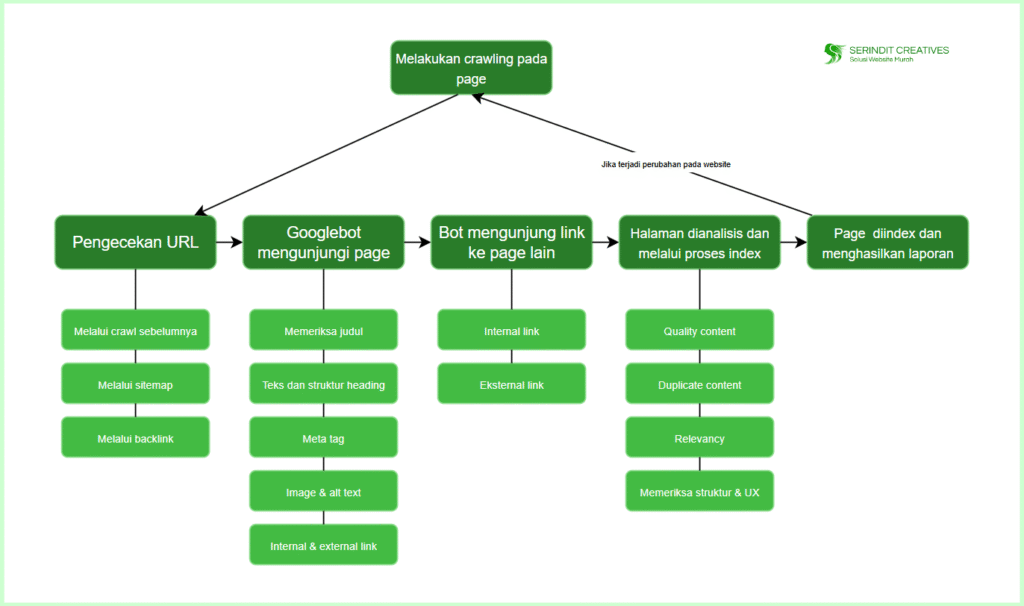
Proses crawling adalah langkah pertama yang dilakukan mesin pencari sebelum menampilkan hasil di Google. Tanpa crawling, Google tidak bisa tahu halaman apa saja yang ada di website kamu. Nah, berikut ini adalah penjabaran lebih lengkap tentang bagaimana proses crawling itu bekerja dari awal sampai akhir:
1. Google Memulai dari Daftar URL yang Sudah Diketahui
Google punya daftar besar URL dari berbagai website yang pernah ia kunjungi sebelumnya. Ini bisa berasal dari:
- Link yang ditemukan saat crawling sebelumnya.
- Sitemap yang dikirimkan pemilik website lewat Google Search Console.
- Link yang ada di website lain yang mengarah ke kamu (backlink).
Dari daftar ini, Google akan mulai menjelajah lagi untuk mencari update atau konten baru.
2. Googlebot Mengunjungi Halaman Tersebut
Google menggunakan robot otomatis yang disebut Googlebot. Bot ini akan mengakses satu per satu halaman dari daftar tadi. Saat mengunjungi sebuah halaman, bot akan membaca kode HTML-nya. Informasi yang dibaca meliputi:
- Judul halaman.
- Teks dan struktur heading (H1, H2, dst.)
- Meta tags seperti meta description.
- Gambar dan atribut alt-nya.
- Internal dan eksternal link.
3. Bot Mengikuti Tautan ke Halaman Lain
Crawling tidak berhenti hanya di satu halaman. Googlebot akan mengikuti link-link yang ada di dalamnya. Ini bisa jadi:
- Link ke halaman lain di website yang sama (internal link).
- Link ke situs lain (external link).
Dari sini, Google menemukan halaman baru yang mungkin belum masuk dalam indeksnya, lalu menambahkan halaman tersebut ke daftar crawling berikutnya.
4. Halaman Dianalisis dan Dikirim ke Proses Indexing
Setelah konten dibaca, Googlebot akan mengirim data itu ke sistem Google untuk dianalisis lebih dalam. Ini termasuk:
- Menilai kualitas konten.
- Menentukan relevansi topik dengan kata kunci tertentu.
- Mengecek duplikasi konten.
- Melihat struktur dan pengalaman pengguna (UX).
Jika semuanya baik, halaman akan diindeks, yaitu disimpan di database Google agar bisa ditampilkan di hasil pencarian.
5. Crawling Ulang atau Refresh
Proses crawling bukan hanya sekali. Googlebot akan datang kembali secara berkala untuk mengecek apakah halaman kamu berubah. Kalau kamu rajin memperbarui konten, Google akan lebih sering meng-crawl dan meng-update indeksnya.
Frekuensi crawling bisa dipengaruhi oleh:
- Seberapa sering kamu update konten.
- Kualitas dan popularitas website kamu.
- Jumlah halaman yang ada di website kamu.
- Struktur internal link kamu.
Tapi, nggak semua halaman bisa atau boleh dicrawl. Kamu bisa mengatur ini lewat file robots.txt atau meta tag “noindex”, yang akan memberi tahu Googlebot: “jangan masuk ke ruangan ini.” Jadi, penting banget buat kamu mengatur file ini dengan benar agar hanya halaman penting yang terindeks.
Crawling juga dipengaruhi oleh crawl budget, yaitu batasan jumlah halaman yang bisa dikunjungi Google dalam periode tertentu. Kalau website kamu besar, pastikan strukturnya rapi dan loading cepat supaya Googlebot tidak buang-buang waktu.
Singkatnya, proses crawling adalah awal mula bagaimana Google menemukan dan mengenal halaman website kamu. Tanpa proses ini, mustahil website bisa tampil di hasil pencarian.
Apa yang Bisa Menghambat Crawling?
Kadang, crawler tidak bisa menjelajah semua halaman website kamu. Berikut beberapa alasan kenapa crawling bisa terhambat:
- Robots.txt Memblokir Akses
File ini bisa memberi tahu crawler halaman mana yang boleh atau tidak boleh diakses. Salah pengaturan bisa bikin halaman penting kamu tidak ter-crawl.
- Struktur Link yang Buruk
Kalau halaman kamu tidak punya link internal yang jelas, crawler bisa kesulitan menemukannya.
- Website Terlalu Lambat
Halaman yang loading-nya lama bisa dihentikan sebelum selesai di-crawl.
- Kesalahan Server (5xx Error)
Kalau server down atau error saat diakses, Googlebot tidak bisa menjelajah.
Beberapa jenis halaman bisa lebih sering di-crawl, contohnya:
- Homepage.
- Artikel populer.
- Halaman yang sering mendapat backlink.
- Blog post terbaru.
Sedangkan halaman yang tidak terhubung ke bagian manapun, atau terlalu dalam dalam struktur website (misalnya butuh 4-5 klik untuk mencapainya), bisa jadi tidak pernah di-crawl sama sekali.
Penutup: Proses Crawling Relevan dengan SEO
Proses crawling mungkin terjadi di balik layar, tapi dampaknya sangat besar untuk kesuksesan website kamu. Dengan memahami cara kerjanya dan melakukan optimasi sederhana, kamu bisa membantu Google lebih cepat menemukan dan menampilkan konten kamu di hasil pencarian.
Tanpa crawling, kamu tidak bisa berharap banyak dari SEO. Karena SEO baru bisa bekerja kalau halaman kamu sudah ditemukan dan diindeks. Jadi, mengoptimasi crawling bukan cuma soal teknis, tapi juga bagian penting dari strategi digital marketing kamu.
Kalau kamu ingin website yang mudah di-crawl, cepat, dan SEO-friendly, kami menyediakan layanan SEO di Serindit Creatives. Mulai dari pembuatan website hingga layanan SEO lengkap, semua bisa kamu konsultasikan langsung dengan tim kami. Jangan lewatkan langkah ini dalam strategi SEO kamu. Yuk, optimasi dari sekarang!